Indic Keyboard
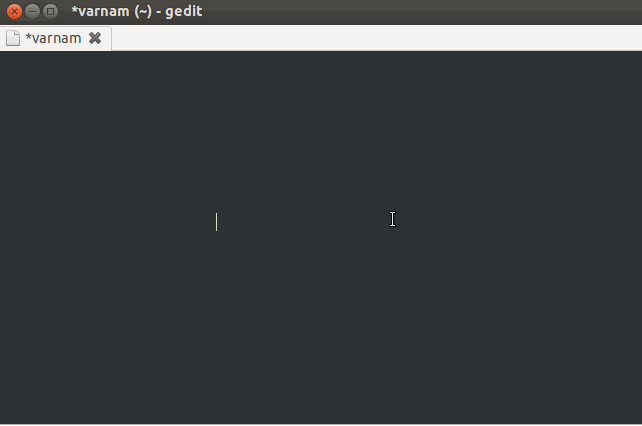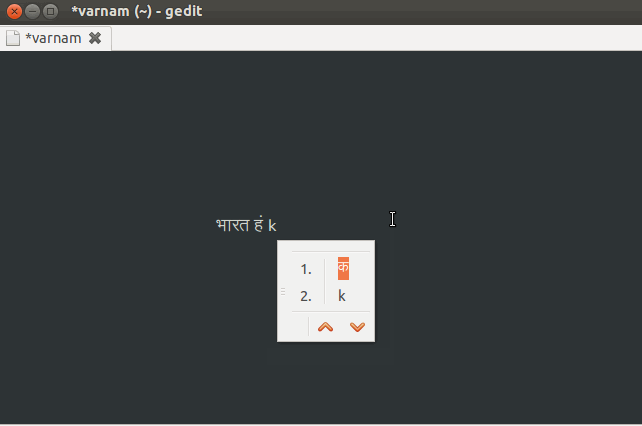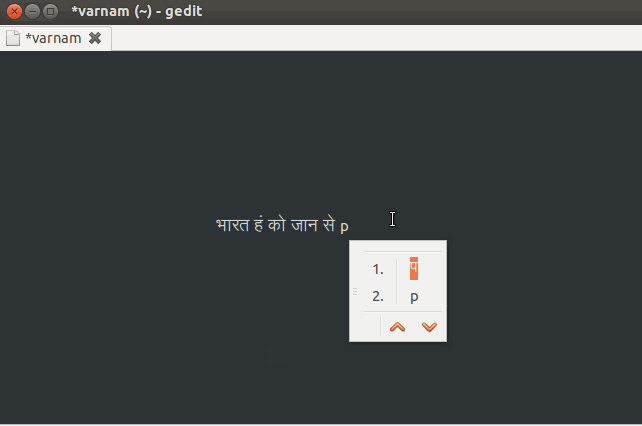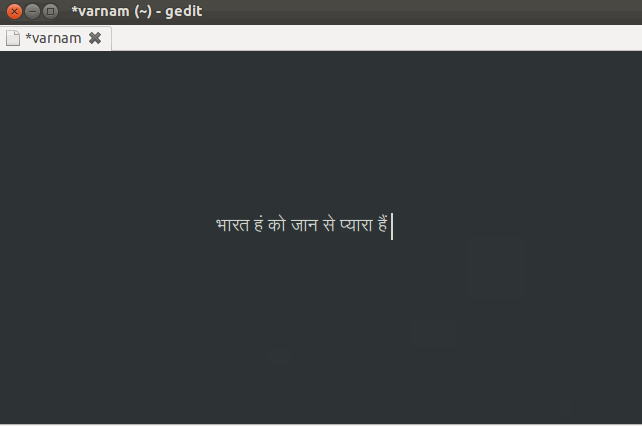
Indic Keyboard is a MOSS Award winning, privacy aware versatile keyboard for Android users who wish to use Indic and Indian languages to type messages, compose emails and generally prefer to use them in addition to English on their phone. You can use this application to type anywhere in your phone that you would normally type in English. It currently supports 23 languages and 57 layouts.